本文提出采用图像遮蔽的方法预训练Vision Transformer
摘要
本文提出了一个使用自监督学习训练的视觉表达模型(vision representation)BEIT,即Bidirectional Encoder representation form Image Transformers
受到BERT在NLP领域优秀表现的启发,本文试图使用**图像遮蔽任务(masked image modeling task)**来对Vision Transformer进行预训练。
具体来说,每张图片将会包含两个view,一个是image patches(例如 16 X 16),和一个visual token。我们首先将图片分解为遗传visual token,然后随机地遮挡一些图片patch,然后传入网络。那么预训练的任务就是将这些被遮挡的image patches复原为原始的visual token。
预训练得到BEIT后,本文直接在预训练的encoder层上增加任务层,将模型 fine-tune到下游任务中。
实验表面在图像分类和语义分割两个任务上,该模型的效果要优于之前的预训练模型。
引言
如果直接将BERT中的mask任务沿用到Vision Transformer,将会发生以下几个问题:
- 由于没有类似语言任务中的单词字典,可以将image patch直接遮盖,所以无法简单的使用softmax进行分类来预测被遮挡的区域是什么。那么一个直接的方式就是将认为是为一个回归任务,来预测被遮盖的patch的原始像素。但这样又会带来另一个问题。
- 逐像素的复原将会浪费对预训练短程依赖和高频细节的建模能力
为解决上述问题,本文提出了一个子监督学习模型BEIT,并提出了一个预训练任务:Maksed Image Modeling(MIM)
这一任务先将图片分解为patches序列,作为模型的输入,此外还对图像进行“token化”:这一技巧再VAE中被使用,漆具体方法是,在与训练之前,先通过自动编码式重建学习一个“图像token化器”,该模块通过学习一个词表,将图像标签化为离散的视觉标签。
接着,在预训练阶段,作者随机的将图像的部分pacth遮挡掉,随后将被遮挡过的图片输入到网络中。模型将学习如何恢复原图片中的这些visual token而不是原始像素。
随后本文将预训练的BEIT应用到两个下游任务中:图像分类与语义分割。实验表明BEIT的表现要好于 from-scratch training和之前的强自监督学习。
本文发现,通过ImageNet标签的**中间微调(intermediate fine-tuning)**可以进一步提升BEIT的性能,微调的收敛速度和稳定性的提高降低了对末端任务的训练成本。此外,我们证明了自监督BEIT可以通过预训练学习合理的语义区域,释放图像中蕴含的丰富监督信号。
结论
本文提出了BERT-like模型的预训练策略,还展示了在不使用任何人工标注数据的情况下自动获取语义区域知识的有趣性质。未来,我们希望在数据规模和模型规模方面扩大BEIT预训练。
方法
图像表示
本文提及的方法中包含两种图像的表示,被名为 image patch和visual tokens。这两种表示在训练期间分别作为输入和输出表示。
Image Patch
2维的图片将被分解为一串patches序列,使得一个标准的Transformer可以直接接受数据。
从公式层面来看,本文将一张图片变换为N个patch,其中, 每个patch,C代表通道数,是输入图像的分辨率,每个patch的分辨率为
接着每个patch会被线性地展平为为一个向量,这一向量与BERT中的word embeddings中的相同。
Image patchs保留了原始像素,并且被用作BEIT的输入特征。在本次实验中,本文将每个图片分为个区域patch,每个patch大小为
Visual Token
与NLP任务中相同,本文将图像表示为一串离散的token,而不是原始像素。具体来看:
本文将图像转化为序列,其中词典包含一系列离散的token序号。
本文使用离散自编码器(dVAE)来学习这个图像token转化器,包含两个模块:tokenizer 和 decoder
其中tokenizer的任务是通过视觉词典将图片的像素x映射到token z。而decoder 学习如何将token z重建为图片像素x,重建的目标函数可以用如下公式表示。由于隐视觉令牌是离散的,模型训练是不可微的,因此使用Gumbel-softmax relaxation来训练模型。此外,在的训练过程中加入了一个统一的先验。
注意一幅图像的视觉令牌数量和图像块数量是相同的,图像字典的大小是8192,本文直接使用了公开可用的tokenizer
骨干网络
L层Transformer Blocks,在输入时额外加入了token [S],使用一维位置编码。
预训练BEIT
本文随机的遮盖了大约40%的patches,被遮盖的区域表示为,接着本位使用了一个可学习的embedding 来代替被遮盖的部分。然后将被处理过的patches序列输入L层的Transformer模型中,最后的隐藏向量被视为输入块的编码表示。对于每一个被mask的位置,本文使用一个softmax分类器来预测该位置对应的visual token 其中表示每个被遮盖的位置,表示被遮盖的图像,为可训练参数。预训练目标似乎最大化log似然,对于当前visualtokens 优化目标如下:
其中D表示训练词典,M表示随机遮盖的位置,表示被遮盖的图像
但本文的训练并不是随机的遮盖,而是采用blockwise masking。对于每个块,将最小patches数设置为16,然后为mask块随机选择一个长宽比,重复上述两个步骤,知道有足够的masked patches,此处设为其中N为图像块的总数,0.4为遮盖的比例。
Fine-Tuning
本实验对三个下游任务进行了fine-tuning:
- 图像分类:使用softmax作为任务层,对学习到的表达形式使用平均池化后,直接使用softmax进行分类,其中是第i个图像patch最后的编码向量,是权重矩阵,C是标签数量。
- 图像分割:使用BEIT作为编码器,使用一些列反卷积作为解码器来进行分割。
- Intermediate fine-tuning:在自监督的预训练之后,本文继续使用更大的中间数据集(例如ImageNet-1K)来训练BEIT。
实验
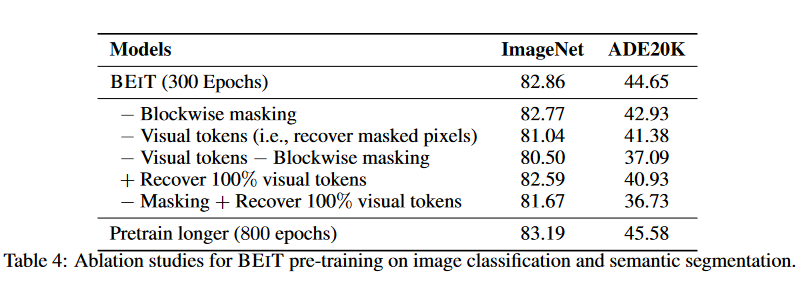
对比了各种自监督学习、从头训练的模型,训练epoch为800
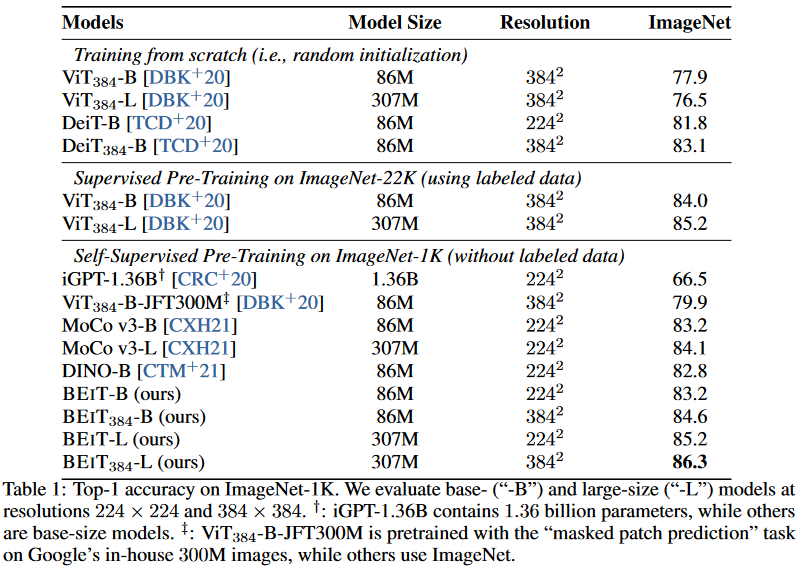
消融实验
消融实验师兄300epoch对模型进行了训练结果如下:
- 使用随机遮盖代替blockwise遮盖,发现后者对于图像分类任务和图像分割任务均更有效,尤其是在图像分割任务中。
- 其次使用预测原始像素代替了原本的预测patch token,结果发现消融后的模型甚至不如直接使用数据集对ViT进行训练。因此本文认为patch token的预测是BEIT成功的关键成分。
- 再次作者同时删除了blockwise遮盖和patch token预测,作者发现甚至对于直接的像素预测,blockwise遮盖也是有一定作用的。
- 恢复所有的visual tokens对于下游任务的表现是有害的。
- 比较累不同training steps下的BEIT,发现使用进行更长时间的预训练会对下游任务实现进一步提升。