摘要
发表于ECCV2022,针对现有基于Transformer的数学公式识别方法中存在的注意力覆盖不足的问题,提出一种新的注意力精炼模块(ARM),将RNN模型广泛采用的覆盖注意力机制巧妙地应用在Transformer中,在不影响并行性的前提下,利用过去的对齐信息精炼注意权重。另外本文还提出自覆盖和交叉覆盖两种模块,利用来自当前层和前一层的过去对齐信息,更好地利用覆盖信息。
背景
Encoder-Decoder架构由于可以在编码器部分进行特征提取,在解码器部分进行语言建模,在HMER领域被广泛应用。虽然Transformer在NLP领域已经成为基础模型,但在HMER任务上性能相较于RNN还不太令人满意。作者观察到现有Transformer与RNN一样会收到缺少覆盖注意力机制的影响,即过解析——图像某些部分被不必要地多次解析;以及欠解析——某些区域未被解析。RNN解码器使用覆盖注意力机制来缓解这一问题。然而,Transformer解码器所采用的点积注意力没有这样的覆盖机制,作者认为这是限制其性能的关键。
不同于RNN,Transformer中每一步的计算是相互独立的。虽然这种特性提高了Transformer中的并行性,但也使得解码器中直接使用以前工作中的覆盖机制变得困难。
为了解决这一问题,作者提出了一种利用Transformer解码器中覆盖信息的新模型CoMER。手RNN中覆盖机制的启发,作者希望Transformer将更多注意力分配到尚未解析的区域。
作者提出注意精炼模块ARM。同时为了充分利用了来自不同层的过去对齐信息,作者提出了自覆盖和交叉覆盖,分别利用来自当前层和前一层的过去对齐信息。作者进一步证明,在HMER任务中,CoMER的性能优于标准Transformer解码器和RNN解码器
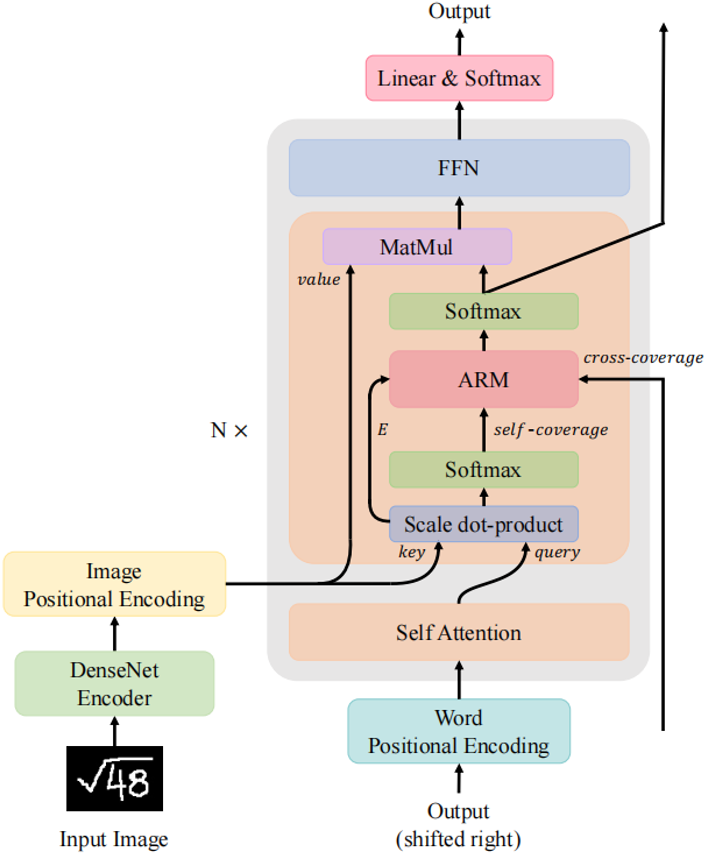
方法
CNN编码器
本文使用DenseNet并在末端增加1*1卷积
位置编码
本文与BTTR作法一致,同时使用图像位置编码和字符位置编码
注意力精炼模块ARM
如果Transformer直接采用RNN式的覆盖注意力机制,将产生一个具有O(TLhd)空间复杂度的覆盖矩阵F∈RT×L×h×dattn,这样难以接受。问题的关键在于覆盖矩阵需要先于其他特征向量相加,再乘以向量va∈Rdattn。如果可以先将覆盖矩阵与Va相乘,再加上LuongAttention的结果,空间复杂度将大大降低到O(TLh),因此作者将注意力机制修改为:

其中相似向量et′可分为注意项和精炼项rt∈RL。需要注意的是,精炼项可以通过覆盖函数直接由累积ct向量生成,从而避免了具有为维数为dattn的中间项。作者将上市命名为注意力精炼框架
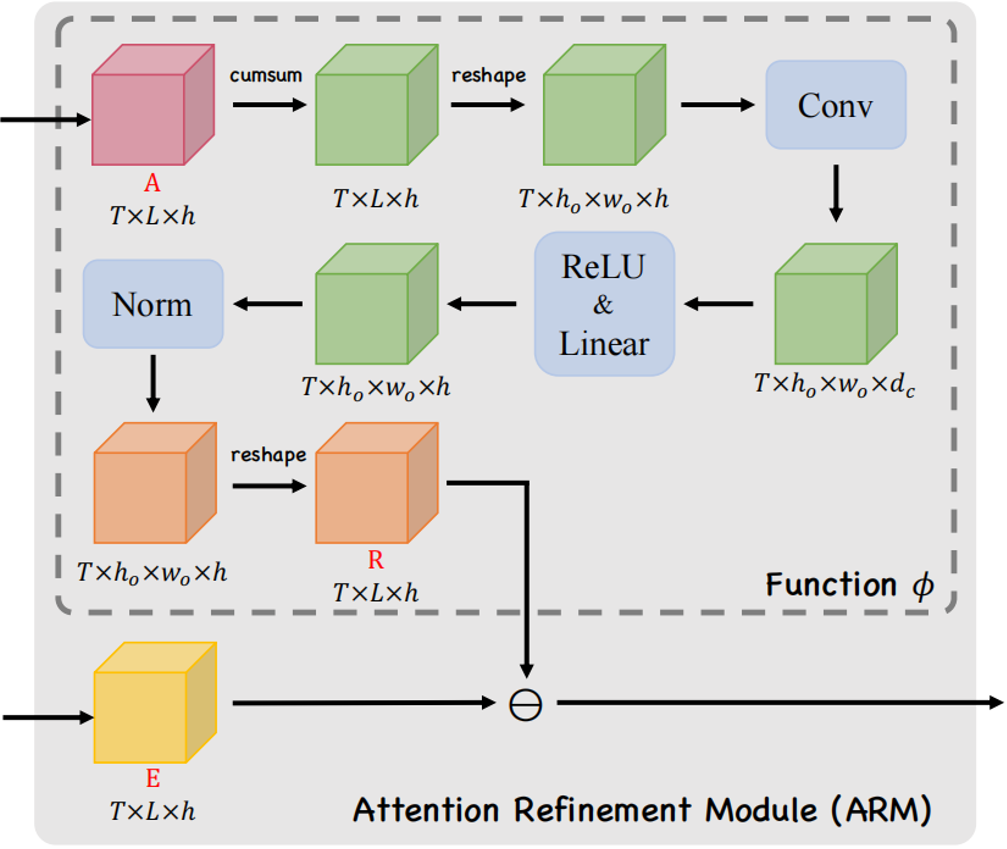
为了在Transformer中使用这一框架,作者提出了如图所示的注意精炼模块(ARM)。可以将Transformer中的点积矩阵E∈RT×L×h作为注意项,精炼项矩阵R需要从经过Softmax后的注意权值A中计算出来。作者使用了注意权值A来提供历史对齐信息,具体的选择会在下一小节介绍。
作者定义了一个将注意力权重A∈RT×L×h作为输入,输出为精炼矩阵R∈RT×L×h
的函数ϕ:RT×L×h→RT×L×h
R=ϕ(A)=norm(max(0,K∗C~+bc)Wc)
C~=reshape(C)∈RT×ho×wo×h
ct=∑k=1t−1ak∈RL×h
其中at是在时间步t∈[0,T)时的注意力权重。K∈Rkc×kc×h×dc代表一个卷积核,*代表卷积操作。bc是一个偏置项,Wc∈Rdc×h是一个线性投影矩阵。
作者认为函数ϕ可以提取局部覆盖特征来检测已解析区域的边缘,并识别传入的未解析区域,最终作者通过减去精炼项R来达到精炼注意力项E的目的。
覆盖注意力
本节将介绍注意权重A的具体选择。作者提出了自覆盖、交叉覆盖以及融合覆盖三种模式,以利用不同阶段的对齐信息。
自覆盖: 自覆盖是指使用当前层生成的对齐信息作为注意精炼模块的输入。对于当前层j,首先计算注意权重A(j),并对其进行精炼
A(j)=softmax(E(j)∈RT×L×h)
E^(j)=ARM(E(j),A(j))
A^(j)=softmax(E^(j))
其中E^(j)代表了精炼后的点积结果。A^(j)代表在j层精炼后的注意力权重。
交叉覆盖:作者利用Transformer中解码层相互堆叠的特性,提出了一种新的交叉覆盖方法。交叉覆盖使用前一层的对齐信息作为当前层ARM的输入。j为当前层,我们使用精炼后的注意力权重:A^(j−1)之前(j−1)层来精炼当前层的注意力项
E^(j)=ARM(E(j),A^(j−1))
A^(j)=softmax(E^(j))
**融合覆盖:**将自覆盖和交叉覆盖相结合,作者提出了一种新的融合覆盖方法,充分利用从不同层生成的过去对齐信息。
E^(j)=ARM(E(j),[A(j);A^(j−1)])
A^(j)=softmax(E^(j))
其中[A(j);A^(j−1)]∈RT×L×2h表示来自当前层的注意权重与来自前一层的精炼注意权重精选拼接。
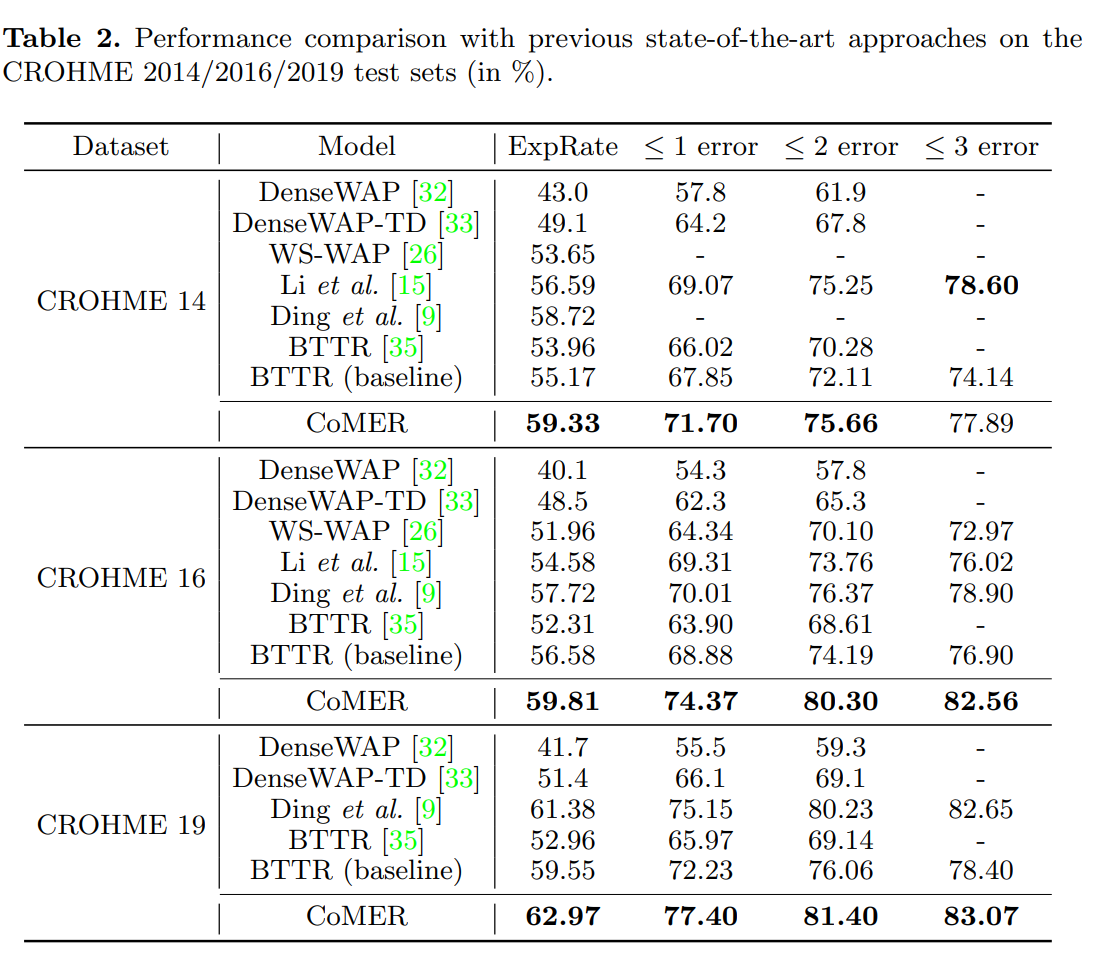
数据集
- CROHME14
- CROHME16
- CROHME19