








python学习笔记,基础语法部分
Into
2021年5月,我收到了来自北京工业大学的调档函,这也许意味着我研究生生活的开始。研究生最终选择了机器学习相关的方向,并且得知导师所在实验室的方向是手写体识别。
说到Machine Learning,据说大多数人使用Python进行其相关的学习与发开,Python其实之前有接触过,并且使用pyGame复刻了一版2048,可以在我的GitHub上看到:

这大概是我大一的时候写的项目了,之后比赛以及训练时都是使用自己更为熟悉的C++,因此Python逐渐变得生疏,于是就有了这篇博客。MPGA就一定会实现!
Make Python Great Again!
参考资料
Get Ready!
使用一门语言进行开发的第一步,大概是环境搭建吧。
搭建环境的方法有多种,最方便的大概使用windows的命令行,输入:
1 | python |
如果你的电脑上尚未配置python的环境,windows自动为您打开windows引用商店,点击安装后,将自动为您修改环境变量。
此时如果再次输入python,即可编写脚本。
 Python%20564b04e5895e443e982a45f45f1c78ee/Untitled.png
Python%20564b04e5895e443e982a45f45f1c78ee/Untitled.pngCoding Now!
环境搭建完成后,就该选择编辑器了,可以使用Jet Brain旗下的PyCharm,非常好用,但由于之前使用VS code进行前端开发,为了避免不必要的存储空间占用,我选择对VS Code进行一些配置,使它能够进行python开发。
首先进入python官网下载安装好VS Code,下载地址:
然后,为了使VSCode更适合于python开发,我们可以利用一款名为python的插件改造我们的编辑器。

然后,新建一个文件夹作为工作区,为该工作区单独配置工作环境,通过一些必要的设置,我们将得到一个方便且强大的python编辑器。
接下来就能愉快的coding了
Python数据类型
数字
- 整数
python整数的表达相对自由,支持以下形式:
1 | a = 100 #普通整数 |
- 浮点数
python中浮点数可以使用如下形式表示:
1 | a = 1.5 #普通浮点数 |
字符串
python中表示字符串,可以使用单引号'或双引号"。
如果使用"包裹,则'不需要进行转译:
1 | a = "I'm Iron Man" |
此外python还支持如下方法,使字符串全部不转译:
1 | a = r"\\\\t\\\\" #此行代码将输出\\\\t\\\\ |
使用'''@'''可以输出多行内容
1 | print('''I'm |
但需要注意,python中的缩进将会被包含在内,如:
1 | if __name__ == "__main__": |
布尔值
python中也存在bool变量,python中使用True和False(区分大小写)表示。
1 | a = True |
bool运算符使用如下方式表示
1 | a = True and Falseb = True or Falsec = not True |
字符串
- 字符串编码
最开始美国人生产计算机时只考虑了美式字符和英文字母,于是创造了只有127个字符转化的ASCII
后来中国人为了适配自己的语言,创造了GB2312
日本人将日语编入Shift_JIS,韩国人将韩语编入Euc-kr
这些操作都导致字符的编码系统及其复杂。于是Unicode诞生了,Unicode编码具有以下特征:
- 将所有语言的字符进行整合
- 无论语言,通常每个字符占用2个字节,生僻字符将占用4字节
但这样又会导致新的问题,ascii中英文字符占用一个字节,但用了unicode将占用两个,这导致了传输时的带宽浪费,因此又出现了UTF-8编码。UTF-8具有如下特点:
- 采用不定长编码,常用字母占1字节,中文3字节,生僻字符占4-6字节。
- 兼容ASCII
计算机内存中为了方便操作与管理,通常采用定长的编码方式,如windows采用的UTF-16就是Unicode的一种,而当对文件进行持久化操作时,通常会为了节约空间而使用变长编码,如UTF-8。
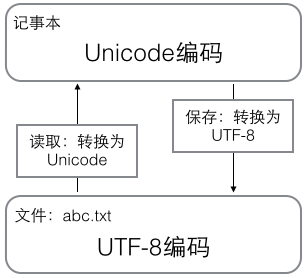 内存中的字符集转换
内存中的字符集转换同样的事也发生在网络上,为了节省带宽传输时,以及网页在显示时直接使用类似UTF-8的变长编码,而服务端则使用Unicode编码以便于管理
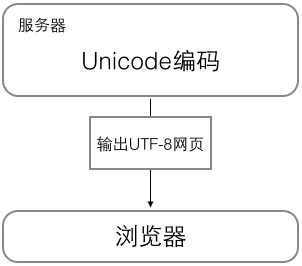 网络中的字符集转换
网络中的字符集转换- python中的字符串
在python3中,字符使用Unicode编码,可以使用如下方式使字符串及其编码进行互转,ord和chr:
1 | a = ord('A') |
还可以直接使用编码来表示字符:
1 | print('\u4e2d\u6587') # 输出'中文' |
pyton中的str如果需要在网络上传播或保存到磁盘上,就需要使用如下操作把str变为以字节为单位的bytes:
1 | a = b'ABC' # 此时每个字符将只占用一个字节 |
以Unicode表示的字符也可通过encode()方法编码为指定的bytes:
1 | print('ABC'.encode('ascii')) |
如果从网络或者磁盘上读出了字节流bytes也可以使用decode()将其转化为str
1 | print(b'ABC'.decode('ascii')) |
如果bytes中只有一小部分无效的字节,可以传入errors='ignore'忽略错误的字节:
1 | print(b'\xe4\xb8\xad\xff'.decode('utf-8', errors='ignore')) |
此外,对于字符串,还可以使用len()方法获取字符串的长度:
1 | len('ABC') |
通常对于python文件而言,会使用如下两行注释来指定编码:
1 | #!/usr/bin/env python3 |
第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
- python字符串格式化
python字符串支持使用如下方式进行格式化:
1 | print('Hello, %s' % 'world') |
此外还可以使用format()进行格式化:
1 | 'Hello, {0}, 成绩提升了 {1:.1f}%'.format('小明', 17.125) |
此外,python还支持一种格式化字符串f-string,该字符串中的{xxx},将会被对应变量替换:
1 | r = 2.5s = 3.14 * r ** 2 |
| 占位符 | 替换内容 |
|---|---|
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
空值
Python中使用None表示空值
1 | a = None |
动态语言
python属于动态语言,赋值时不需要指定变量类型
比如,进行值交换时可以使用如下方式:
1 | a = 10 |
常量
python中通常用全大写的变量名来表示常量,如:
1 | PI = 3.14159265359 |
但是这并不意味着PI这个量就是一个无法给便的值了,只是习惯上认为这是一个常量,PI仍然是一个变量且他的值仍然能被改变。
除法
在python中,除法有两种,分别是/和//使用区别如下:
1 | a = 9/3 |
List
Python中的list为一种有序集,具有如下特定:
- 支持增删
- 支持随机访问
- 下标从0开始
- 下标为-x时表示从后向前数的索引
1 | classmates = ['Michael', 'Bob', 'Tracy'] |
- 插入
python支持两种插入方式,分别是append和insert,前者将直接在末尾进行插入,后者支持指定位置插入:
1 | classmates.append('Adam') |
- 删除
list支持使用pop方法进行删除:
1 | classmates.pop() |
- 修改
通过重新赋值的方式即可对list中指定位置的元素进行修改:
1 | classmates[1] = 'Sarah' |
- 特性
list允许存放不同类型的元素,如:
1 | l = ['apple',123,True] |
并且允许list嵌套:
1 | s = ['python','java',['html','css'],'c++'] |
并且使用len方法求长度时会得到第一层list中的元素个数:
1 | len(s) = 4 |
以此方式可以进行任意层数的嵌套
tuple
元组,另一种形式的有序表,具有如下特征:
- 不支持增删改操作
- 允许定义空元组
- 允许随机访问
- 必要时使用tuple代替list可以保护
- tuple,list可以相互嵌套
- 定义
定义tuple时,使用()
1 | t = (1,2) |
但当定义只有一个元素的tuple时,需要注意避免如下歧义:
1 | t = (1) |
- “可变”tuple
使用list与tuple的嵌套可以使tuple变得部分可变:
1 | t = ('a','b',['A','B']) |
具体情况如下图所示

Python条件语句
1 | if <条件判断1>: |
Python循环语句
for
Python允许使用for...in语句对有序表进行遍历:
1 | # 外部定义的list |
此外对连续自然数进行便利还能直接使用range(),注意该函数从0开始
1 | list(range(5)) |
while
Python中同样允许在循环中使用continue以及break
1 | n = 0 |
特殊数据结构
dict
dict是python中的一种类似map结构,每个元素由一对{key,value}组成,使用方法与map类似:
1 | d = {'Michael': 95, 'Bob': 75, 'Tracy': 85} |
存储同样的数据,用dict实现时的查找效率往往比用list实现更高效,原因如下:
1 | # 对于存储上例中的数据,使用list实现时往往需要这样实现 |
为什么dict的查找速度如此之快呢,这就需要了解dict的底层实现了。
-
python3.6及以下使用普通的hash方式实现dict,即对key值进行hash,将key与value存储到hash对应的位置中去。也就意味着使用这样的简单hash方法会导致数据结构无序(unordered);并且,为了保证尽量少的hash冲突发生,往往剩余空间小于当前总容量大1/3时,就会对dict进行扩容,这就导致随着存储内容的增多,dict可能逐渐变得稀疏,造成空间的浪费
-
python3.7对hash结构进行了改进,首先python会维护一张由list实现的index表,indices,这种表用来存放下标映射关系,也就是,对于存放第一组数据,进行如下操作:
- 计算出key 的下标值index = getIndex( hash(key) )
- indices[index] = 0
- Entities[0] = {key,value,hash(key)}
这样做有什么好处呢,
首先,真正存放数据的Entities中存放的数据是顺序且连续的;
其次,这样存储,indices是稀疏的,但其中仅仅存放一个表示下标的数字,消耗的空间大大减小。
查找过程如下:
- 首先通过hash函数得到indices中的下标,index = getIndex( hash(key) )
- 访问Entities[index]得到数据。
这样做,每次查找需要多查一次,但多出来的查找时间复杂对为O(1),时间开销的增加并不明显。
更详细的内容可以参考下面的博客:
可见,dict的查找效率只与hash函数有关,与存储的容量没有直接关系。
dict还支持有如下操作:
1 | d.get('Bob') # 获取d中key为Bob的值,如果没有,返回None,输出到控制台时表现为什么都没有d.get('FK',-1) # 获取d中key为FK的值,如果没有返回-1d.pop('Jack') # 删除d中key为Jack的值(包括key),并返回该值'Jack' in d # 如果key为Jack的值包含在d中,返回True,否则返回False |
由于dict中的key需要进行hash变换,这就要求了dict中存放的key必须是可hash的,也就是说必须是确定的值,比如数字,字符串,自定义类,而可变的list则无法作为key。
为什么str是不可变对象呢:
对于这样的操作:
1 | a = 'abc'b = a.replace('a','A')print(a)print(b)# 对于a而言,进行a.replace('a','A')操作后,a中保存的值并没有变。 |
对于第一条赋值语句而言,变量a可以理解为只是指向’abc’的指针,而真正的字符串对象则是’abc’本身。
也就是说不变对象调用自身的任意方法,都不会对自身造成改变,而是创建新的对象并返回。
set
python中的set同STL中的set,也可以理解为只有key的dict,因为底层逻辑是一样的,都是进行hash,只不过set是指用hash来保证不会有同样的元素被添加,定义set时需要使用一个list来创建。
1 | s = set([ 1, 1, 2, 2, 3, 3, 4]) # 将得到一个set,内容为[1,2,3,4] |
注意set是无序的,使用set()去重时很可能得到不一样顺序的结果,主要原因是set存储是利用hash进行的,次序根据hash的值而定。但有时对纯数字的list进行set创建操作可能会得到有序的结果,原因可能是某些解释器的hash函数对数字进行hash时,得到的就是该数字。
set还包含如下操作:
1 | s.add(2) # 向s中加入一个值为2的元素,如果重复,则结果不会改变s.remove(2) # 从s中删除值为2的元素 |
函数
定义
python使用如下方式进行函数的定义:
1 | def functionName(param): |
python中函数再返回多个值的时候,会将返回值用tuple封装,而多个变量可以同时接受一个tuple,因此下面的写法被认为是正确的:
1 | import math |
空函数
1 | def emptyFunction(param): |
参数
python中的函数支持许多定义函数参数的方法,包括如下几种:
- 位置参数
1 | def function(param): |
- 含有默认值的参数
1 | def function(param = 'default value'): |
但是,需要注意的是,如果将参数的默认值设为可变对象,那么会出现一些问题,比如:
1 | # -*- coding: UTF-8 -*- |
注意到我调用了三次使用默认参数的fun,但是,函数好像有记忆一样,后两次fun使用的默认对象与上一次使用的是同一个!这显然是反直觉的,原因是python会在内存中开辟一块空间来存放参数的默认对象,为了节约空间,每当某个参数适用默认对象时,python只需要将其指向默认对象存放的空间就行了。但是如果默认对象使用可变对象,那么可能会存在某些操作,是的内存中的可变对象发生改变,导致每次赋予的默认值都不一样。
因此使用默认值有如下规则:
使用带有默认值的参数时,尽量将默认值设置为不变参数
但是如果一定要让某个函数的默认值为某个可变对象,使用None是最安全便捷的方法:
1 | def fun(l = None): |
有时我们可能还想让间隔开的两个参数使用默认值,但由于python默认值检测是顺序的,考虑到这一点,python提供了如下方法来避免歧义:
1 | def fun(a=1, b=2, c=3, d=4): |
- 可变参数
有时候我们可能无法确认传入参数的数量,为此,python提供了可变参数,此法允许我们传入任意数量的参数。当然用tuple或者set作为参数同样可以实现类似的功能,但是可变参数省去了创建set或tuple的操作,并且当传入参数为空时,不像set或tuple一样需要判空。
1 | def function(*param): |
但当我们需要传入tuple或者set时,传入的tuple或set会和参数构成一个二维结构:
1 | # -*- coding: UTF-8 -*- |
为了避免这种情况,python允许使用如下方式来避免歧义:
1 | # -*- coding: UTF-8 -*- |
- 关键字参数
改参数允许传入0个或任意个含参数名的参数,这些参数再函数内部自动组装为dict,定义时使用**加以区分:
1 | def person(name, age, **kw): |
关键字参数可以起到扩展函数功能的作用,比如在编写注册功能时。
还能自己组装dict后再传入:
1 | extra = {'city': 'Beijing', 'job': 'Engineer'} |
此处kw获得的dict是extra的一份拷贝,对kw的改动不会影响extra
- 命名关键字参数
关键字参数允许传入任意值,当我们需要限制关键字参数的名字时,可以使用命名关键字参数,如:
1 | def person(name, age, *, city, job): |
*之后的参数被视为明面关键字参数
如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*了:
1 | def person(name, age, *args, city, job): |
命名关键字参数必须传入参数名,如果没有会报如下错:
1 | person('Jack', 24, 'Beijing', 'Engineer') |
次数由于没有指定参数名,python解释器认为调用时所提供的4个参数均为position arguments,即位置参数,而函数定义时只有2个位置参数。
命名关键字同样支持缺省值:
1 | def person(name, age, *, city = "Beijing", job): |
参数顺序
python中为了确保解释器对参数的解析正确,上述的5中参数需要按照一定顺序进行排列,即:
位置参数,默认参数,可变参数,命名关键字参数,关键字参数
1 | def f1(a, b, c = 0, *args, **kw): |
除了上述方法以外,还可以使用一个tuple和一个dict调用上述函数
1 | args = (1,2,3,4) |
虽然允许使用的参数组合有如此多种,但是使用过多的组合会导致函数接口的可读性下降
递归
递归几乎是一门涉及到函数的语言必讲的内容,此处强调一下尾递归:
尾递归:如果一个函数中所有递归形式的调用都出现在函数的末尾,我们称这个递归函数是尾递归的。当递归调用是整个函数体中最后执行的语句且它的返回值不属于表达式的一部分时,这个递归调用就是尾递归。
谈到递归,就不得不谈起另一个词:函数栈
递归虽然具有优秀的易读性,但过多的递归调用会占用很大空间的函数栈。
而尾递归,或者说“伪递归”可以通过优化使其只占用常数级的栈空间。
递归的执行过程可以理解为由两部分组成:
- 递归
- 回溯
而尾递归能偶被优化的原因,就在于尾递归的回溯过程可以省略。
下面来看几个例子:
1 | def fact1(n): |
以上两个函数都能用来计算阶乘,但区别在于fact1中的回溯我们认为是有意义的,因为递归调用自身后,该层需要下一层递归返回的结果进行表达式运算
而fact2中的当前层只是简单的对后一层结果进行返回。
因此这就意味着,我们不需要在进入下一层梦境之前,对当前层的“环境”进行保存。那么我们在函数栈中,便不需要为后一层开辟新的栈空间,而只是简单的让他覆盖掉当前层所在的栈帧。
此外,由于回溯时不需要做任何运算,只需要对结果进行保存,尾递归显然可以使用循环来代替。事实上,在一些没有循环结构的语言中,通常就是使用尾递归的方式来实现循环。
尾递归转化为循环的方法详见如下博客:
Python高级特性
切片
如果需要取一个list或tuple的某个片段,通常的做法是新建一个空list或tuple然后使用循环将其取出,但python提供了更方便的办法:
1 | L = ['Michael', 'Sarah', 'Tracy', 'Bob', 'Jack']L[0:3] |
python中切片操作提供了三个可选择参数:
note info [起始位置:结束位置:取数间隔]
注意事项:
- 其中取数是取到结束位置的前一个标号
- 起始位置默认为0
- 取数间隔是指每k个数取一个
迭代
例如遍历一个list或tuple的过程我们可以称之为迭代。
python中的for具有很多特殊的操作。比如使用for...in 来完成C++11中加入的新特性来遍历数组或其他数据结构中的每一个元素
1 | //C++ |
1 | #python |
事实上python中的所有可迭代对象,都能通过for...in来遍历。比如dict
1 | d = {'a':1,'b':2,'c':3}for key in d: print(key)# a# b# c |
由于dict的存储并不是按章顺序存储的,因此迭代顺序不一定是abc
默认情况下,dict迭代的是key
如果要迭代value,则需要使用:for value in d.values() ,如果需要同时迭代key和value,则需要使用如下方式:
1 | for k,v in d.items(): |
那么我们该如何判断某对象是否输入可迭代对象呢?
需要通过如下方法:
1 | from collections.abc import Iterable |
而当我们需要对某个list进行类似C中的下标迭代,可以使用enumerate关键字将list转化为索引-元素对
1 | for i, value in enumerate(['A','B','C']): |
列表生成
python提供了一种非常方便的列表生成方式:
variable = [out_exp for out_exp in input_list if out_exp == 2]
如:
1 | [x * x for x in range(1, 11) if x % 2 == 0] |
此外还可以使用二重循坏:
1 | [m + n for m in 'ABC' for n in 'XYZ'] |
当我们使用if限制列表生成的元素时,if...else的使用需要特别注意:
- 当if放在for后进行限定时,不能使用else
- 当if放在for前进行限定时,必须使用else
这是因为for前面的部分是一个表达式,它必须根据x计算出一个结果。因此,考察表达式:x if x % 2 == 0,它无法根据x计算出结果,因为缺少else,必须加上else
例如:
1 | [x if x % 2 == 0 else -x for x in range(1, 11)] |
生成器
生成器也是一种可以用来生成列表的工具,他与生成式最大的不同在于:生成式是将列表中的所有元素提前计算好,而生成器则等到你需要时再计算当前位置的值。
简单生成器的创建较为简单,只需要将生成式的[]改为()即可:
1 | L = [x * x for x in range(10)] |
生成器可以使用如下两种方法访问:
1 | # 方法1 |
此外,还能将函数改造为生成器,当函数中使用关键字yield,进行返回时,此为生成器的高级用法,比如使用生成器打印杨辉三角:
1 | def triangles(): |
需要注意的是,python函数在返回可变对象时返回的是对象的地址
此外,使用函数定义的生成器也能设置返回值,但需要通过捕捉StopIteration异常来查看返回值:
1 | def fib(max): |
迭代器
迭代章节聊过可迭代对象:Iterable
而迭代器,则是像生成器一样,不仅可以使用for遍历,还能被next()函数调用并不断返回下一个
可以使用如下方法进行判断:
1 | from collections.abc import Iterator |
此外还能用iter()方法把可迭代对象转化为迭代器:
1 | isinstance(iter([]), Iterator) |
Python中的Iterator对象表示一个数据流。
即
- 能作用与
for循环的对象都是Iterable类型 - 能作用与
next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列
事实上Python中的for本质上就是通过不断调用next()函数实现的。
上下文管理器和with关键字
对于系统资源如文件、数据库连接、socket 而言,应用程序打开这些资源并执行完业务逻辑之后,必须做的一件事就是要关闭(断开)该资源。
通常情况下我们打开一个文件需要做如下操作:
1 | def test1(): |
但如果对该文件的操作非常之多,有几十上百行,最后的关闭代码及那个里实际执行代码非常远,甚至有时会忘记关闭文件。因此python为我们提供了更方便的方法:
1 | def test2(): |
使用with关键子我们就不需要进行显示的关闭文件了,运行with中的代码块后,将自动关闭该文件,也就是回到进入with代码块之前的状态。
使用with关键字的方法更为简洁,它的实现原理是什么,这就涉及到上下文管理器。
任何实现了 __enter__() 和 __exit__() 方法的对象都可称之为上下文管理器
例如我们自定义一个上下文管理器来测试with的执行过程:
1 | class Test4(object): |
此外我们还可以使用contextmanager装饰器来自定义上下文管理器:
1 | from contextlib import contextmanager |
但是with本身并没有异常捕获的功能,但是如果发生了运行时异常,它照样可以关闭文件释放资源。如果运行时发生了异常,就退出上下文管理器。调用管理器__exit__()方法。
with不仅能用来管理文件,还能管理锁,链接等等,如管理线程锁的例子:
1 | #管理锁 |