本文提出了一个树形结构的Transformer,用于代码生成
摘要
代码生成系统主要是基于输入的自然语言来生成其描述的代码。目前最好的基于神经网络的代码生成模型包含两个方面的问题:
- 一种是长依赖问题,其中一个代码元素往往依赖于另一个距离较远的代码元素。
- 另一个问题是结构建模,因为程序包含丰富的结构信息。
本文提出了一个船新的基于树形结构的神经网络结构,称为TreeGan,其使用Transformer中的注意力机制来解决长依赖的问题,此外引入了一个全新的AST reader(encoer)将语法规则和AST结构纳入网络。
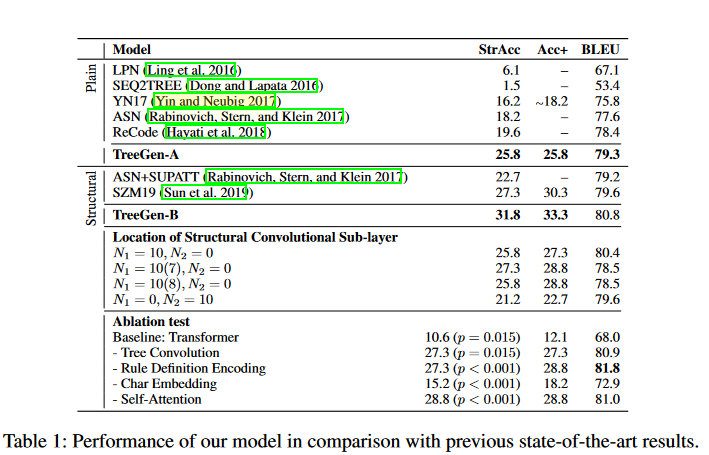
本文使用Python benchmark,炉石传说,以及两个语义解析基准,ATIS和GEO来对TreeGan进行评价。TreeGan比以往的SOTA模型在炉石传说任务上高了4.5个点,并且在ATIS(89.1%)和GEO(89.6%)两个标准上,在所有基于神经网络的方法中脱颖而出。
本文对模型进行了消融实验以便对模型的组件又更好的理解。
引言
随着神经网络的发展,类似Seq2Seq、Seq2Tree等模型被应用于代码生成领域,尤其是SOTA的方法,根据预测语法规则序列来生成代码,意思是说系统从已经生成的代码中保存了部分抽象语义树(Abstract syntax tree(AST)),然后预测用于拓展节点的语法规则。
语法规则的分类算法面临这两大主要挑战:
- 长依赖问题。一个代码元素也许依赖于另一个距离非常遥远的元素
- 代码结构的表述。前人的工作表明树形结构信息对于代码建模至关重要,但“扁平”的网络架构,例如RNN,很难很好地捕捉到这些信息。
本文试图将Transformer用于代码生成领域以改善长依赖的问题,但原始的Transformer网络并不能充分利用树形结构。
其次对于上文提到的无法利用结构信息的问题,标准的解决方法是将一个节点和其结构相邻节点的向量表示进行结合,作为一个结构卷积子层的输出,这一灵感在图/树卷积网络中使用,但标准的Transformer中并没有这样的结构卷积子层,而且在何处加入这些层并不明朗。
作者一开始的假设是将structural convolution加入到Transformer的每一个block中去,这一做法的核心假设是:当对某一节点和他的邻接节点进行卷积时,向量表示将主要包含原始节点的信息。但随着decoder中block的推进,这些向量表示将逐渐丢失原有的节点信息。因此本实验只在decoder的开头的几层添加结构卷积子层。
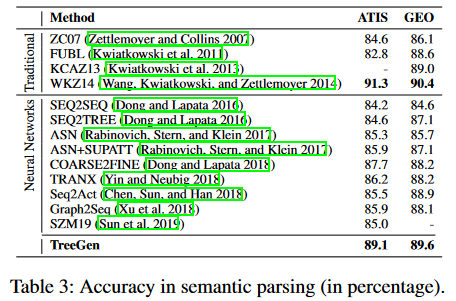
总体上来说,TreeGen模型主要包含三个部分:
- natural language(NL)reader作为encoder,对文本描述进行编码
- AST reader(开头的几层Transformer decoder)使用结构卷积子层对之前生成的部分代码进行编码
- Transformer decoder blocks,结合以AST中需要被拓展的节点作为query,以及先前的两个encoders来预测接下来的语法规则。
结论
本论文提出了TreeGen来完成代码生成的任务。使用Transformer中的注意力机制来解决长依赖的问题,使用AST reader编码器将语法规则和AST structure结合到模型中。
模型被用于Python dataset 、炉石传说和ATIS、GEO两个测量指标上,实验结果表明本文提出的模型表现比现存模型都好,同时本文进行了in-depth消融测试,实验表明模型中的每一个部分都有着重要意义。
方法
本文提出的TreeGen网络总体结构如下:
语法规则预测
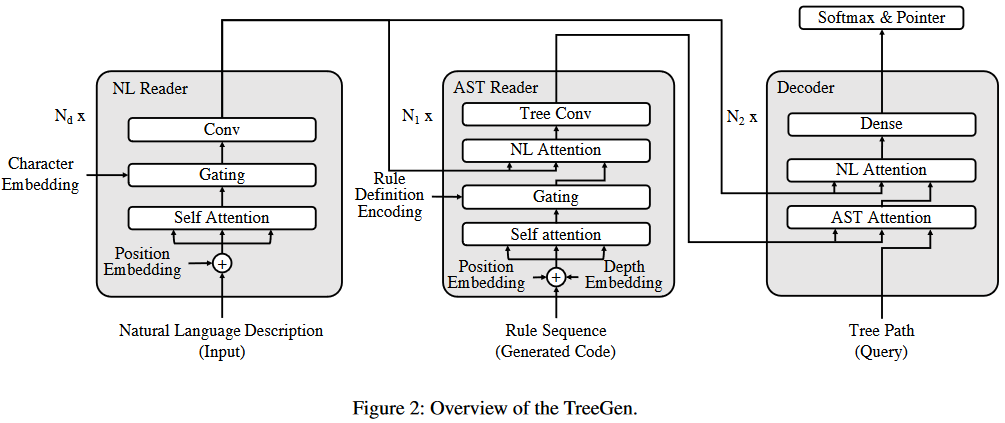
本章介绍了如何将代码生成转化为一个序列语法规则预测的模型。程序可被分解为一些上下文无关的语法规则,并被解析为一个AST,例如下图中所示是一条python代码的抽象语法树(AST),其中虚线框代表结束符,实线框代表非结束符。
该方法可以视为根据语法规则对一个非结束节点进行拓展。这个过程一直持续到遇到结束叶子节点。
最终整个对AST的预测任务可以表示为:
其中表示规则序列中的第i个规则。用这种方法表示后,本文的任务是训练一个模型来计算
NL Reader
自然语言的描述性输入决定了代码的功能,在炉石传说任务中,输入是半结构化的描述,而在ATIS和GEO测试中使用的是自然语言。
对于一段输入的描述,本文首先将其标签化为一串标签其中L代表输入的长度,然后每个标签将被分割为一系列字母,其中S代表中字母的个数。所有的标签和字母都会通过embedding层被表示为实值向量和
输入文本表示
本文使用一个全连接层对输入文本进行编码,称为Character Embedding。表示为其中表示权重,并且字母序列将被padding成一个预定义的最大长度M。经过全连接层后,本文使用一个Layer Normalization进行归一化。得到的向量之后会被送到NL reader中,在gating子层中与word embeddings整合。
NL Reader网络结构
NL reader包含一些blocks(个)的堆叠,每个block中包含三个子层:
- self-attention
- gating mechanism
- word convolution
每两个子层间包含残差连接。以此来提取特征。
Self-attention
子注意力机制层遵循了Transformer中的结构,使用多头注意力机制来获取长依赖信息。
本文中的子注意力机制同样使用了位置编码来保留位置信息,但在原本的位置编码上做出了一些小小的改动:
其中b代表当前处于第b个block中。d表示维数,即embedding的大小
Transformer block通过多头注意力机制学习到的非线性特征产生了一个矩阵:
然后多头注意力机制的计算如下:
为了使表示更简洁,此处省略了块数b,H代表头数,代表权重。对于每个头,计算注意力权重如下:
其中表示每个特征的长度。
QKV的计算如下:
W代表模型参数,是Tranformer block的输出。
Gating Mechanism
提取完特征之后,作者使用一个基于softmax的gating mechanism将字母embeddings的信息进一步整合。对于第i个词,作者使用一个线性变换层,根据计算一个控制向量。用于字母embedding计算的softmax权重根据经过一个线性变换得来。用于Transformer输出的softmax权重根据经过另一个线性变换得到。接着gate会用以下的方式计算:
gate将会用于对Transformer的层级输出、字母embeddings的特征,根据线性变换得到的向量继续权重分配:
与多头注意力的计算类似,最后gating mechanism的输出为:
其中表示一个矩阵,其中的元素是
Word Convolution
最后,使用两层卷积层对gate层的输出提取特征:
其中l表示第i层卷积层,特征的计算方式如下:
其中W代表模型参数,,k代表卷积窗口的大小。
代表gate层的输出。这一层使用的是分离卷积。
对于第一个和最后一个词,作者为其添加了0作为padding。
两层卷积之间使用GELU作为激活函数。
那么最终经过三层结构构成的encoder后得到的特征为
AST Reader
作者设计了一个AST reader来提取已经生成的代码的AST结构信息。尽管本文设计的模型是根据预测规则来生成代码,但如果只依赖这些规则而缺少程序的具体印象不足以预测下一跳规则,因此本文提出的AST reader将会考虑各种信息,包括预测的规则和树形结构。
首先使用规则序列来表示代码,其次使用注意力机制对规则进行编码,最后使用树形卷积层来结合编码表示和每个节点的祖先。
AST表示
规则序列编码
使用table-lookup embeddings生成的实值向量来表示用于构建AST的规则。
规则定义编码
上述的table-lookup编码将语法规则视为原子标签,并且会丢失规则包含的信息。为了解决这一问题,作者通过规则定义编码来加强规则的表达。
对于语法规则,其中是父节点,为子节点,可以是结束节点,也可以是非结束节点,序号i表示规则的ID。结果使用表示
与输入的文本类似,作者使用全连接层对各个符号代表的table-lookup编码进行编码。并且序列同样的会被padding为最大长度。
随后规则定义特种使用另一个全连接层进行计算:
其中是规则的table-lookup编码,是规则表示的内容编码,并且在这一阶段作者继续使用父节点进行计算,随后使用一层layer normalization进行归一化。
位置和深度编码
由于同样使用自注意力机制计算,作者向语法规则中加入了位置信息。
序列位置信息使用了与描述文本相同的方式,使用来表示规则的序列位置编码。
接着,由于序列位置编码无法表示AST结构中的深度信息,因此引入深度编码(depth embedding)。如果此时使用规则r来拓展一个节点,作者使用其父节点的深度来表示这条规则的深度。以此方法,作者使用来表示语法规则序列的深度编码。
AST Reader网络结构
AST Reader同样使用多个blocks堆叠而成,中共包含个block,每个block包含四个子层:
- Self-Attention
- Gating Mechanism
- NL Attention
- Tree Convolution
前3个子层都包含一个环绕的残差连接,并且每个子层之后会使用Layer Normalization进行归一化。
Self-Attention
输入是规则编码,位置编码和深度编码,即
使用自注意力机制提取的特征如下
Gating Mechanism
作者想要将规则的内容编码融合到特征中,本模型使用了与NL Reader中相同的Gating Mechanism,融合之后的特征表示为
NL Attention
该层将编码器中特区的特征与解码器中的特征表示求多头注意力机制,最后得到的特征表示为
Tree Convolution
如果只考虑上述子层的信息,reader很难将节点以及其祖先节点的信息结合,因为一个节点可能与非常远的一个祖先存在相关性。因此传统的Transformer很难捕获到这类信息。
本文将AST视为一幅图,使用一个邻接矩阵M表示向量图。如果是的双亲结点,那么,假设所有的节点都以特征的形式表示,那么他们的双亲特征可以用特征本身乘以邻接矩阵得到:
其中代表第i个节点特征的双亲节点特征。对于根节点的父节点,本文将其映射为根节点本身。
应用于当前子树的树形卷积窗口定义如下:
其中代表军基层的权重,kt代表窗口大小(本文实验中设为3),l是卷积层本身,第一层卷积的输入为:
其中
在AST reader的最后一层,本文添加了两个额外的卷积层,f表示激活函数,部署在两层之间,使用的是GELU。
最终AST reader输出的特征为
Decoder
与AST reader相同,解码器包含了个块的堆叠,每个块包含了三层,每层之间包含一个残差连接,以及Layer Normalization的组合。
decoder使用非终节点作为query进行拓展,受到近期论文的启发,查询节点表示为一条从根节点到代拓展节点的路径。本文将该路径上的接待你表示为实值向量,接着对其使用全连接层得到输出路径
接下来使用两层注意力层来将AST reader和NL reader的输出进行整合。
本文首先使用了一个AST attention层,对AST reader提取得到的特征和Query提取特征,Q是由计算得到;K和V是从代码特征中计算得到。本文使用NL attention进一步整合了输入描述文本的信息,Q由计算得到;K和V由输入的描述文本计算得到。
最后的Dense层包含两个全连接层,第一个全连接层使用GELU作为激活函数,用于提取特征进行预测。
训练与推断
本文最后使用softmax对decoder最后一层的输出特征进行预测。同时本文引入pointer network(本质上是一个注意力层),该网络能直接从自然语言描述中复制一个token,在这种情况下,最后的语法结果是,其中是一个被拓展的非终结符,a是一个终结符。这也的指针机制对用户自定义标识符(例如变量和函数名)是有帮助的。
softmax规则预测和指向网络的选择由另一个门控机制控制,同样计算decoder最后一层的特征。总体预测改了由如下公式给出:
i代表规则ID,D预测规则的集合、C类似的规则集合,其中a表示一个出现在自然语言描述中的结束符。
代表使用某一类型预测规则的概率,并且(每一条规则的概率)分别由带有sigmoid和softmax激活函数的两个单层感知器计算,这些层的输入为特征,表示decoder的最后一层特征。
指针网络由如下公式计算得到:
通过最大化对参考程序的负对数似然损失来优化模型。
推理从一个开始规则开始,使用一个特殊的符号snode拓展根标号。当AST中的所有叶子节点均为终结符时,递归推理结束。在预测阶段,本文使用beam search,大小为5。进行beam search会排除无效的规则。
实验
评价实验
本文使用炉石传说、ATIS和GEO进行实验
炉石传说
benchmark包含665张不同的炉石卡片,每张卡片包含半结构化的描述以及正确的python代码,平均长度84个token。半结构化的描述包含卡牌名、类型、以及一个由自然语言描述的卡牌技能。
在将卡片描述预处理为令牌序列时,现有方法考虑了两种方法。第一个(称为扁平预处理)将整个描述视为扁平文本,并通过空间或时期等标准分隔符来划分标记。第二个(称为结构预处理)将描述视为半结构化的,并且总是将属性视为一个token。在本实验中,本文同时考虑这两种方法,并将扁平预处理对应的结果记为TreeGen - A,结构预处理对应的结果记为TreeGen - B。本文遵循train - dev - test拆分。
本文使用以下指标作为评价:
- StrAcc:与基本真值具有完全相同的tokens序列的程序的百分比
- BLEU score:用于衡量生成代码与参考代码在tokens级别上的相似度
- Acc+:它是手动评估的,允许在StrAcc之上为每个测试用例进行变量重命名。
实验对网络的配置如下:除第一层为1024维外,其余全连接层隐藏尺寸均设置为256维。作者在每个层之后都设置了dropout,概率设为0.15,网络使用Adafactor的默认设置进行优化。
本文的模型在Plain和Structural的预处理方式上都获得了最优成绩,并且在一块泰坦XP上子需要18s训练一轮,CNN需要180s,RNN需要49s
消融实验
为了验证结构卷积的作用,作者进行了如下实验:
- 为所有Transformer块增加结构卷积()
- 只为前7层Transformer块增加结构卷积()
- 只为前8层Transformer块增加结构卷积()
- 不为Transformer块增加结构卷积()
实验结果表明2 > 3 > 1 > 4
随后作者作者将模型与传统的Transformer进行比较,后者是一种没有进行有效结构建模的Transformer。准确率( p值小于0.001)提高了21个百分点,BLEU评分提高了12分,证明了AST reader的有效性。
接着,作者将AST Reader中的树形卷积层替换为两层全连接层,依次去掉了字符嵌入、规则定义编码、自注意力层。实验结果表明,标识符编码、缓解长依赖和结构信息显著影响准确率。
ATIS&GEO
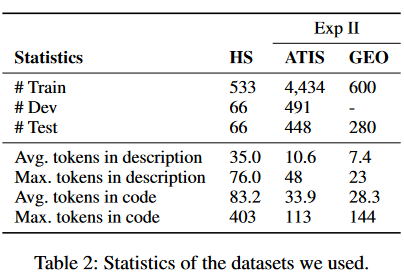
本实验使用了准确率作为度量,其中树准确度的度量避免了模糊误差,即子节点的顺序可以在连接节点内改变。embedding size和隐藏层的size变为了128维,其他设置与炉石传说中的设置相同。数据集的设置如下:
实验表明本文的方法准确率略低于WKZ14,该传统方法使用了大量模板,因此难以扩展到新的数据上。然而,本文的模型直接采用了炉石传说数据集,并取得了所有神经模型中最高的准确率。最终结果如下: