








标题
基于多尺度特征融合的互学习脱机手写数学公式识别
研究内容
- 使用Transformer Decoder替换原本的RNN,由此改善欠解析和过解析的问题,同时对更称序列有更好的识别效果
- 设计不同的特征融合策略,环节细节再低分辨率特征映射中丢失严重的问题
- 学习是写字体与打印字体的语义不变性
- 设计新的损失函数
实现
多尺度特征融合
本章针对DenseNet对细粒度特征的提取不够准确的问题进行了分析,认为细节会再低分辨率特征映射中丢失,导致欠解析的现象。
因此考虑在进行特征提取的编码器阶段获取两个尺度的特征信息,进行特征融合。
本文对比了以下三个方案:
- 损失融合:
- 编码器最终会提取出两套不同尺度的特征图,分别输入解码器后,计算出两个尺度的损失,将俩者取平均值,使用最终的平均损失作为下一阶段梯度更新的依据。
- 特征融合:
- 同样是在编码阶段提取出两套不同尺度的特征图
- 将尺度较小的特征图上采样到与大特征图相同的尺寸后进行拼接得到最终的特征图。
- 对融合后的特征进行特征解码。
- HRNet特征提取:
- 丰富网络的结构,增加多条并行路径,分别提取不同分辨率的特征图
- 提取到四个不同尺度的特征图并最终进行融合。
下面是三种方式的网络结构图:
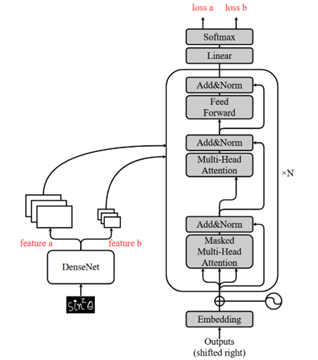
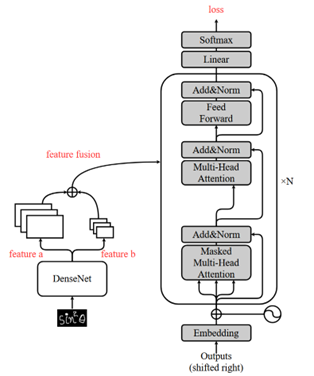
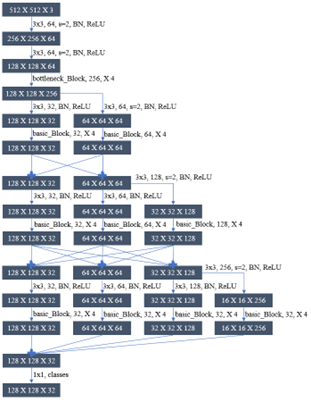
实验
最终通过对比实验得到如下结果:
| Dataset | Methods | ExpRate | <= 1 err | <= 2 err | WER |
|---|---|---|---|---|---|
| 2014 | |||||
| BTTR | 53.96 | 66.02 | 70.28 | - | |
| BTTR_MSLoss | 55.74 | 70.36 | 77.77 | 11.54 | |
| BTTR-MS-fusion | 55.25 | 73.39 | 80.53 | 10.46 | |
| BTTR-HRNet | 48.78 | 69.00 | 76.83 | 12.00 | |
| 2016 | |||||
| BTTR | 52.31 | 63.90 | 68.61 | - | |
| BTTR_MSLoss | 51.44 | 67.31 | 77.42 | 12.06 | |
| BTTR-MS-fusion | 52.31 | 69.66 | 78.12 | 10.96 | |
| BTTR-HRNet | 48.30 | 65.48 | 75.85 | 12.63 | |
| 2019 | |||||
| BTTR | 52.96 | 65.97 | 69.14 | - | |
| BTTR_MSLoss | 52.29 | 69.06 | 76.65 | 11.54 | |
| BTTR-MS-fusion | 53.72 | 72.43 | 80.03 | 9.86 | |
| BTTR-HRNet | 49.71 | 69.58 | 77.06 | 11.40 |
最终选择了BTTR-MS-fusion作为解码器
互学习机制
使用LaTex标签生成的打印字体作为额外的辅助信息。
文章借助GAN网络的思想,分别提取手写体和打印体的特征进行预测,然后使用判别网络去鉴别特征来自于手写还是打印。
本文使用的鉴别方法是在最终的概率分布输出阶段进行上下文向量的匹配,从而避免引入新的判别网络造成模型参数进一步扩大。