








摘要
本论文设计了:
- 版面分析:基于特征瀑布的多尺度融合模块,通过不同尺度上的图像进行相互融合进行版面分析
- 混合数据识别:阶段空间注意力模块,混合文本中存在二维空间结构,该模块在训练时能有效地注意到文本行中二维结构的上下区域,提升神经网络对二维特征的表达能力
- 数据集:真实场景下学生手写文本,分别构建了混合检测和识别数据集
实验结果
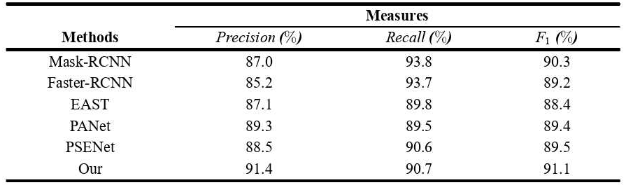
混合检测数据集:综合指标分数91.1%
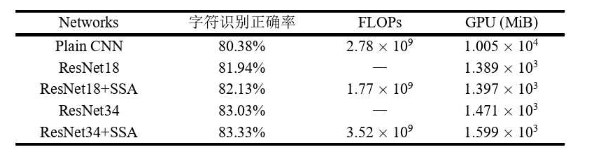
混合识别数据集:准确率83.33%
方法
流程分析
数学文本识别流程:
-
版面预处理
- 缩放、旋转、去噪
-
文本行内部结构分析
- 通过语义分割将二维公式转化为一维序列
- 内部语义结构分析,将文字和公式分开处理
- 将数学公式划分为:
- 数值
- 根式
- 指数
- 分数
- 文本行整体分析
- 对真实场景下的手写体数学文档,进行了级别的标注
-
识别模块
- 文本行序列识别
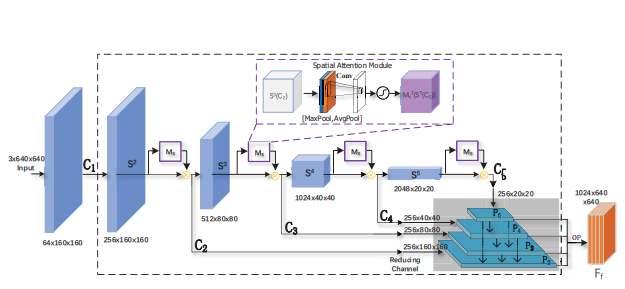
基于多尺度特征瀑布融合的检测网络
思维基础
特征金字塔网络(Feature Pyramid Network, FPN),该网络包含三条通路:
- 自下而上的特征提取路径
- 自上而下的特征强化路径
- 横向连接
该方法相比于图像金字塔,该网络计算量更小,同事丰富每一层级的语义信息。
多尺度特征瀑布融合模块
深层网络得到的特征图会有全局性的感受视野,含有强语义信息
浅层网络得到的特征图会有局部性的感受视野,还有丰富几何特征
本文中特征瀑布融合**(Feature Waterfall Fusion, FWF)**模块。
该模块包含三条通路:
- 自下而上的特征提取路径(Bottom-up Pathway)
- 特征融合的瀑布流路径(Waterfall-flow Pathway)
- 横向连接(Lateral Connection)
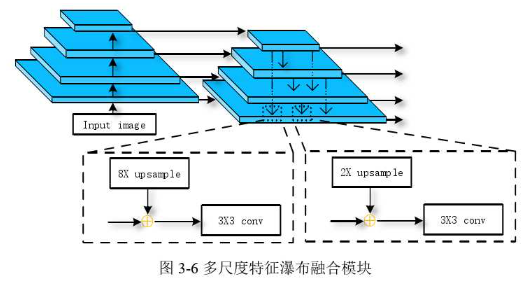
特征提取路径使用ResNet输出四个不同尺寸的特征图,顶部特征图尺寸最小但语义信息最强,底部的图片分辨率最高语义信息最弱。
横向连接层首先使用一个kernel=1,stride=1,padding=0的卷积核将每一个特征图的通道数调整为固定值,上图中使用黄色异或符号表示
瀑布层会将箭头末端代表的特征图融合进箭头指向的特征图中,融合规则如下所示:
某层的特征将被其下所有层融合
即如图右侧最顶层特征将被其下三层融合。
融合方式类似瀑布,因此而的名称。
融合方式,以左侧虚线框中4层与1层合并为例:
- 使用双线性插值法进行8倍上采样
- 同像素累加
- 由于上卷积存在混叠效应,最后需要通过kernel=3,stride=1,padding=1的卷积进行特征平滑操作
由于需要进行同像素累加操作,第2层与第1层的融合则只需要进行2倍上采样即可,如右侧虚线框中所示。
该模块的主要特征是,相比特征金字塔只将低分辨率特征图加入与其最近的一次特征图中,本模块瀑布式的将低分辨率特征图加入到其下的每一层,是所有特征图都具有较强的语义信息。
文本检测网络
在ResNet的基础上结合瀑布式融合模块
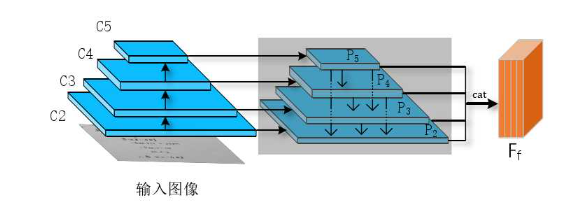
最后的用于预测文本框,由4个特征图组成,拼接之前对分别做上采样,使得通道数为D,长宽分别为,最后得到
渐进式规模扩张后处理
后处理采用渐进式规模扩张后处理(Progressive Scale Expansion, PSE)
该算法的核心思想来源于BFS
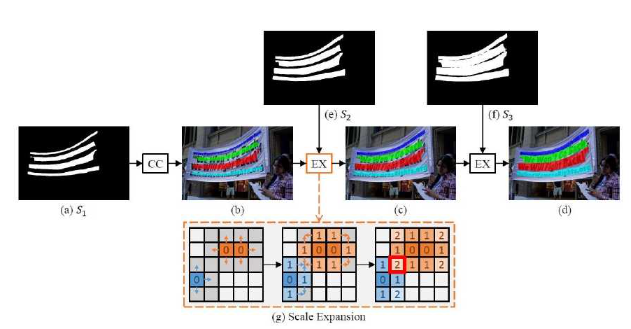
计算伪代码如下:

其中符号T和P式算法扩张产生的中间结果,Queue表示队列,Neighbor()表示文本像素p的相邻像素集,符号GroupByLabel()式根据Label对中间结果分组的操作,符号表示像素q被预测为实列内核的一部分
手写文字公式混合识别
研究难点
- 数据集较少
- 书写风格不同
- 版面随意
基于阶段空间注意力的识别网络
卷积注意力模块
卷积注意力模块(Convolutional Block Attention Module, CBAM)通过提升模型对图像中关键区域的表达能力,告诉网络该注意图片的什么地方,在图片的空间维度上和通道维度上对特征进行一直或强化。
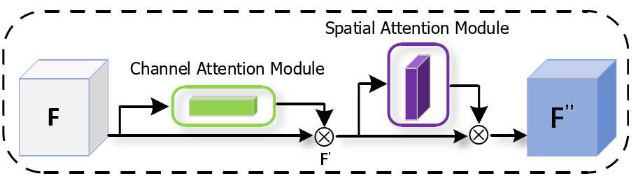
该模块首先根据通道注意力机制产生一个尺寸为的一维注意力图,与F进行像素相乘,得到中间结果,然后再通过空间注意力图机制产生一个尺寸为的二维注意力图,与进行像素相乘最后输出包含通道和空间两个维度权重的特征图
阶段空间注意力(Stage Spatial Attention, SSA)
在手写体数学文本行识别任务中,告诉模型重要区域在哪能提升识别准确率,因此此处指采用卷积注意力模块中的空间注意力子模块来捕获公式的二维结构,而不采用通道注意力子模块
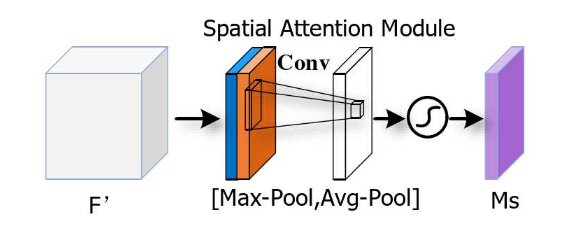
如图所示的过程是SSA中提取出空间注意力图的过程:
- 首先对输入的中间特征进行一次通道维度上的**最大池化(Max-Pool)**得到,即蓝色区域
- 然后对输入的中间特征进行一次通道维度上的**平均池化(Avg-Pool)**得到,即蓝色区域
- 对和按照相同位置进行像素拼接操作,得到
- 接下来通过kernel=3,stride=1,padding=3的卷积核将通道数调整为1
- 为了抑制和凸显重要区域,用Sigmoid函数将特征图上的值域压缩为0-1之间,得到
- 最后将与输入特征图进行像素乘法,就得到了空间注意力特征图
识别网络构建
由于**残差网络(ResNet)**本身的分成结构,本网络使用残差网络作为基础架构

该结构使用了5类残差网块,分别是RestNet18、RestNet34、RestNet50、RestNet101、RestNet152,此处省略了第一次卷积运算,对于任何的原始输入图片,残差神经网络分别四次输出中间的特征图:
因此每一个阶段空间注意力模块会分别生成注意力图:
该网络参数表如下:

总体设计
- 手写数学文档文本行的检测使用渐进式规模扩张后处理算法,该方法能分离间距紧密的文本实列
- 混合文本序列识别采用卷积神经网络CNN和循环神经网络RNN的框架结构
- CNN使用嵌入有阶段空间注意力的ResNet
- RNN为双向LSTM
- 损失函数为CTC
分割网络损失函数设计
使用类似聚类算法的思想对文本行像素进行聚类,采用类似**像素聚合网络(Pixel Aggregation Net, PANet)**的损失函数,生成两个掩码标签:完整掩码和内核掩码
整体损失函数如下:
其中用来促使不属于内核K的像素与其之间距离大,属于内核K的像素与其保持较近距离:
- 表示文档中所有文本行的实例总和
- 表示一行文本行实列
- 定义了属于的像素和文本内核之间的距离
- 超参数设为0.5,用来过滤比较简单的数据
- 是像素的相似度向量表示
- 是内核的相似度向量表示
用来保证不同内核之间的距离足够大:
- 超参数设置为3,用来保证不同内核之间的距离的绝对值要大于
和分别作为文本区域和文本内核的损失,考虑到文本行区域和非文本行区域分布的不平衡性使用Dice Loss计算文本实列的分割结果和文本内核的分割结果:
和两个超参数用来协调四个部分,分别被设置为0.5和0.25,学习率设置为0.001,使用权重衰减来避免过拟合,设置为0.0005,迭代次数设置为300
结果采用F1分数,即H-mean进行衡量,同事保持较高的精确率和召回率:
对比结果:
序列识别损失函数设计
训练使用**CTC(Connectionist Temporal Classification)**进行模型优化
采用Adam优化器对网络进行训练,学习率设置为0.001,迭代次数设置为100
效果对比
缺陷
- 文本行内部结构分析中,上游语义分割误差会影响到下游识别模块的性能,造成累计误差。
- 进行行内部结构分析人工标注工作量大
- 手写文本行内容倾斜问题比较突出,本位未对文本行进行图像校正
- 本文使用的数据集规模较小,可以使用GAN网络来生成更多更逼真的数据。