







机器学习简述
机器学习的定义
历史上主要有两位学者对机器学习进行过定义,反别是Arthur Samuel和Tom mitshell,下面分别给出介绍
Arthur Samuel
Arthur Samuel——编写世界上第一个棋类游戏人工智能程序
他对于机器学习的定义如下:
def: 机器学习是,赋予计算机学习能力,且该能力不是通过显著式编程获得
非显著式编程
让计算机自己总结规律的编程方法
收益函数:
我们通常规定正在特定环境下,计算机做某些行为会带来某些收益,我们称它为收益函数
在规定了行为和收益函数后,让计算机自己去找最大会收益函数的行为
Tom mitshell
而Tom mitshell——在其书《Machine Learning》中对机器学习的定义为:
def: 机械学习,就是对于一个任务T,衡量完成T好换的性能指标P,以及计算机获得的经验E,计算机从经验E中学习,使得,计算机完成任务T的性能指标P逐步提升,即:计算机在T上的被P衡量的性能,会随着经验E的增加而提高
机器学习任务的分类
监督学习
对于:
- 垃圾邮件识别
- 人脸识别
这类的机器学习任务,需要为数据打标签(Labeling for training data),才此情况下,经验E是是训练样本和标签的集合,由此我们可以得到监督学习的定义:
def: 所有经验E都是人工采集并输入计算机的,将这类输入计算机训练数据同时加上标签的机器学习称为监督学习(Supervised Learning)
在此类机器学习中,算法必须知道预测什么,即目标变量的分类信息
此外还能通过数据标签的存在与否对监督学习进行分类,分为:
- 传统监督学习
- 半监督学习
- 非监督学习
传统监督学习
def: 传统监督学习(Traditional Supervised Learning)中,每一个数据标签都有数据标签
传统学习中主要的算法有:
- 支持向量机(Support Vector Machine)
- 人工神经网络(Neural Networks)
- 深度神经网络(Deep Neural Networks)
非监督学习
def: 如果所有的训练数据都没有对应的标签,则称为非监督学习(Unsupervised Learning)
非监督学习的数据中没有类别信息(标签),也不会给定目标值。在无监督学习中:
- 将数据集合分成由了类似的对象组成的多个类的过程称为
聚类; - 将寻找描述数据统计值的过程称为
密度估计;
此外,非监督学习可以减少数据特征的维度,一遍我们可以使用二维或三维图形更直观的展示数据信息。
由定义,我们可能会产生一个问题,对于没有数据标签的数据,我们如何对数据进行分类。
对此我们需要做出如下假设:
- 如果同一类的训练数据在空间中距离最近
- 根据样本空间中的空间信息
- 设计算法将它们聚集为两类
从而实现无监督学习,其中主要算法包括:
- 聚类(Clustering)
- EM算法(Expectation-Maximization algorithm)
- 主成分分析(Principle Component Analysis)
半监督学习
def: 如果训练数据中一部分由标签一部分没有标签,称这种机器学习为半监督学习(Semi-Supervised Learning)
为了节约为数据打标签的成本,由于半监督学习使用少量的标注数据与大量未标注数据进行训练的特性,近年半监督学习逐渐成为热点
另一种分类方式
基于标签的固有属性,我们可以将监督学习分为:
- 分类
- 回归
分类
如果标签是离散的值,则将这种学习成为分类
如人脸识别算法,就是分类任务,如:
- 给出两张人脸,判断是否为同一人,可以用0表示是,1表示否
- 从大量照片中,按照人脸将照片分类,则可以用表示不同的人
这些都是离散的值
回归
如果标签是连续的值,则将这种学习成为回归
例如设计算法预测房价的走势,标签为平均房价,训练样本为时间
总结
对于分类、回归、聚类、密度估计,在此将这些操作的相关算法以及能够解决的问题进行汇总
| 监督学习算法 | 算法用途 |
|---|---|
| k-近邻算法 | 线性回归 |
| 朴素贝叶斯算法 | 局部加权线性回归 |
| 支持向量机 | Ridge回归 |
| 决策树 | Lasso最小回归系数估计 |
| 非监督学习算法 | 算法用途 |
|---|---|
| K-均值 | 最大期望算法 |
| DBSCAN | Parzen窗设计 |
强化学习
对于:
- 下棋
- 自动驾驶
这类机器学习任务,经验E是由计算机与环境互动获得的,我们只需要定义这些行为的收益函数(Reward Function),对行为进行奖励和乘法,并且计算机能够根据这些奖励和乘法,改变自己的行为模式,从而最大化收益函数
由此可以得到强化学习的定义:
计算机通过与环境的互动逐渐强化自己的行为模式的机器学习称为强化学习(Reinforcement Learning)
但对于AlphaGo而言,起初是通过监督学习,通过高手对局的视频,形成一个初始的围棋程序,在对该程序进行强化学习提成其性能。
机器学习算法的过程
-
特征提取(Feature Extraction):
在这一步中会从样本中抽象出一些用于做分类的特征
-
特征选择(Feature Selection)
从1中抽象出的特征中分析,选出最能有效进行分类的特征,以此构建机器学习系统
-
根据2中选出的特征构建特征空间(Feature Space)
-
选用不同的算法对特征空间进行划分
基于2中选择的特征构建算法
PS:
对于3中选择算法这一步,比如可以选择:
支持向量机(Support Vector Machine),其中包含三种内核:
- 线性内核
- 多项式核
- 高斯径向基函数核
再次列举一个构建特征空间的例子,特征空间可以按照特征的个数任意指定维数:
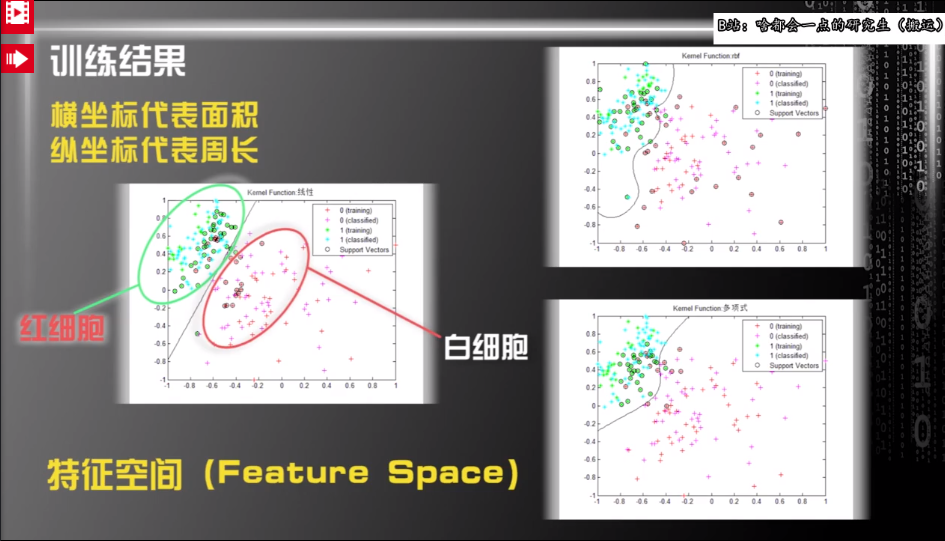
在特征空间中包含的几个关键词:
-
维度
人对于三维以上的事物缺乏想象力,但目前的机器学习算法可以较为精确的处理三维以上的数据
-
标准
使用不同的标准,对某一些区域的划分会有区别
没有免费午餐定理
定理 4.1 1995年
因此没有任何情况下都最优的机器学习方法
对于NFL定理中提及的先验分布而言,我们可以用如下例子进行理解:

其中空间上距离接近的样本它们属于同一个类别的概论更高就是一种先验分布,这就意味着机器学习算法是基于某些先验分布来进行预测的学科。
这就意味着在学习过程中,我们不能片面夸大某个定理的作用,要对开发新的算法保持探索的精神。
此外该定理还提醒了我们机器学习的本质:基于有限的已知数据,在复杂的高维特征空间中预测未知样本的属性和类别
如何选用合适的算法
选用机器学习算法需要考虑以下几个问题:
- 使用机器学习算法的目的
- 想要完成的任务
- 了解数据的特征
- 首先考虑机器学习
算法的目的以及想要完成的任务:- 如果要预测目标变量的值,则可以选择监督学习算法;
- 否则可以选择无监督学习算法。
- 确定选择监督学习算法后,需要进一步明确目标变量的类型:
- 如果目标变量是离散型,则可以选择分类算法;
- 如果是连续性,则可以使用回归算法
- 其次需要考虑实际的数据,应该充分了解数据,对数据了解的越充分,越容易创建符合实际需要的应用程序,主要应该了解数据的以下几个特征:
- 特征值是
离散型变量还是连续型变量 - 特征值中是否有
缺失的值,何种原因造成 - 数据中是否有
异常值 - 某些特征发生的
频率如何
- 特征值是
- 通过对数据的充分了解,可以帮助我们缩小算法的选择范围,而由NFL定理可以知道,一般并不存在最好的算法和可以给出最好效果的算法,一般发现最好算法的关键环节就是反复
调试和迭代
开发机器学习应用程序的步骤
- 收集数据:通过多种手段收集数据,比如
爬虫等,也可以使用开源数据源 - 准备输入数据:
- 得到数据之后,还必须确保数据格式符合要求,使用
标准的数据格式可以融合算法和数据源,方便匹配操作 - 还要为机器学习算法准备
特定的数据格式,一般某些算法要求目标变量和特征值是字符串,而另一些算法要求是整型
- 得到数据之后,还必须确保数据格式符合要求,使用
- 分析输入数据:主要是人工分析得到的数据,确保数据中没有
垃圾数据 - 训练算法:将前两步得到的格式化数据输入到算法,从中抽取信息
- 测试算法:
- 对于监督学习,必须已知用于评估算法的目标变量值
- 对于非监督学习,也必须用其他评测手段来检验算法的成功率
- 如果不满意算法的输出结果,不改变算法的前提下,问题常常与数据的收集和准备有关
- 使用算法:将机器学习算法转化为应用程序,执行实际任务,以检验上述步骤是否可以在实际环境中运行